
Divvying up data

Data is central to the success of any ML project, yet most ML courses say little about how data should be used in practice. In this post, I’m going to describe a few ways in which people commonly use data, explain why these are sometimes sub-optimal, and outline better ways of approaching data usage. To keep things simple, I’m only going to consider the situation where you have a single dataset to work with.
Tweak it til you beat it
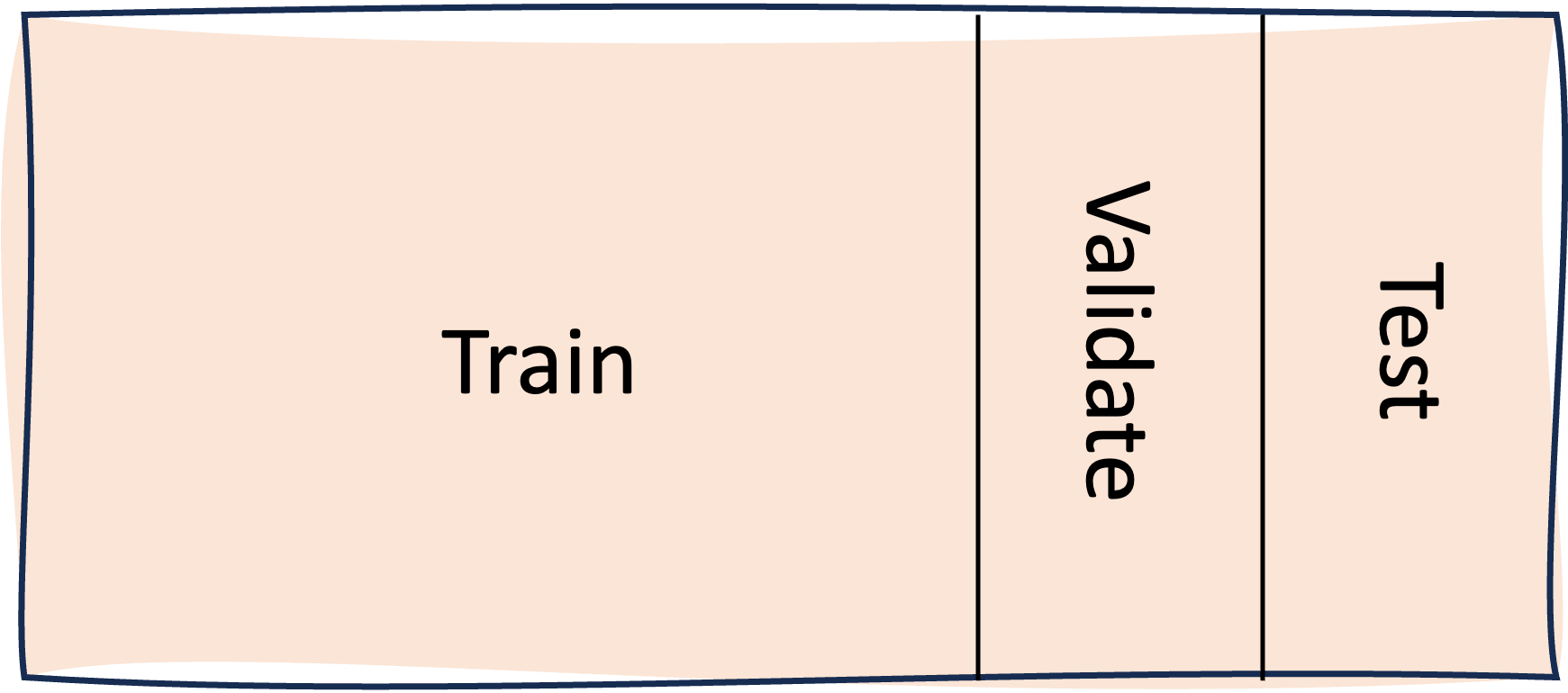
So, let’s say you’ve done the standard thing and split your dataset three ways, into train/validate/test sets. You take the training data, train a model, and then you use the validation data to improve the fit, by doing things like early stopping. You then take a peek at the test score, and find it disappointing. Naturally, you start tweaking the hyperparameters of your model, i.e. things like the number of layers in a neural network, or the number of trees in a random forest. And you keep doing this until your test score is great.
The problem here is that the test set is being used to guide modelling decisions. This might sounds like a minor issue, but it’s not, because it means the test set is basically being used to choose between different modelling directions. Therefore, the test set has become an implicit part of the training process, and ultimately the model will overfit it. So, the test set may appear great, but the test set is no longer a reliable measure of greatness.
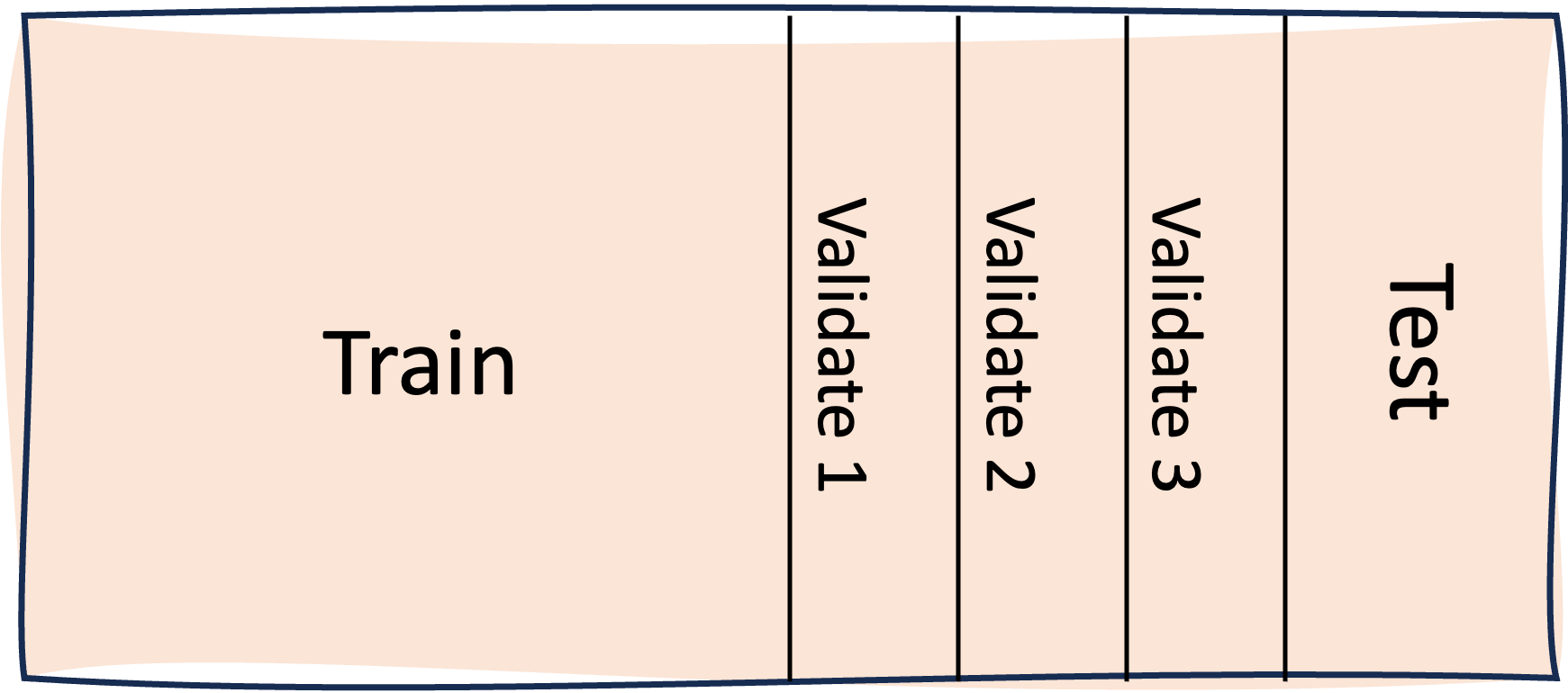
What you should do in this situation is use the validation set score to guide the training process. However, the more you use the validation set, the less useful it will become. That is, if you’re using the validation set for early stopping, hyperparameter optimisation, and potentially other modelling steps (e.g. feature selection), then you’ll quickly overfit it. What you really need is multiple validation sets. So, maybe one for early stopping, another one for hyperparameter optimisation, and potentially others. This is something to consider when working out your data requirements.
The crowd say no selector
Now, imagine a slightly different scenario where you want to try out a bunch of different modelling approaches, see how they compare, and then go with the one that works best. Again, it’s common for people to approach this situation with a standard training/validation/test split, using the training and validation sets to configure and train each model, and then doing a comparison on the test set to pick the best model.
What’s wrong with this? Well, the test set is no longer directly being used to guide training, so it’s not quite the same thing as tweaking til you beat it. However, the test set is being used multiple times, i.e. to evaluate each model. Due to a fun statistical phenomenon called the multiplicity effect, each time you use the test set, you reduce how reliable it is as a measure of greatness. This again comes down to overfitting — if you measure multiple models using one test set, then you’re increasing the chance of finding a model that just happens to overfit that data, rather than really being the best.
Things get even more troublesome if you want to train models multiple times and look at the average performance. This is a sensible thing to do, but you end up using the test set lots of times. If you then pick the best trained model using the test score, it’s quite likely it will be one that’s overfitted the test set, rather than being objectively the best model.
The way around these issues is pretty much the same as before. You need to use a validation set to do model selection (i.e. to pick the best one), and use the test set only to measure how good the selected model is. Hence the silly title1 for this scenario, since currently there’s no explicit selector. If you have limited data, then you could use the same validation set you use to do early stopping and such like. But the more you overload a validation set, the less helpful it becomes in guiding decision making, so only do this if you have to.
In practice, in this scenario the term hold-out is often used for the data you use to test the selected model, and with this naming it’s also common to refer to the data used for selection simply as the test set. Life would be easier if people used the same names consistently, but what can you do? But having said that, hold-out is the better term in my opinion, since it emphasises the fact that this data is being kept aside until the end. And ideally you should keep it well out of reach until then.

Cross-validator your data
Cross-validation is often seen as a solution to people’s data woes. Hence the tortuous title of this scenario, which only works if you use the British pronunciation of data.
Cross-validation, at least in its basic form, is quite simple. Split your data into n (typically n is 10) equally-sized chunks. Then repeat training and evaluation n times, using a different chunk for testing each time, lumping together the other n-1 chunks for training and validation. Finally, take the average of all the test scores, and use this to capture the performance of the model.
There are some good things about cross-validation. First, it’s good when you want to train a model multiple times and look at the average performance. It’s better than the fixed train/validate/test scenario in this respect, since it also captures robustness to changes in the training and test data. It’s also better in terms of data efficiency, because you can get get a robust measure of performance whilst using more data for training.
The downside is that you end up training n models. If you want to actually use a model, you then have to pick one. This is hard to do, because each of them was evaluated on a relatively small amount of data, so their test scores are likely to be unreliable. So, the one with the highest test score may or may not be the best, and you have no way of measuring how good it is — without using more data. And so the solution is again the same: keep some data aside to evaluate your final selected model.

Although you do have one other choice here. You can take the n models and ensemble them together, and the resulting ensemble is likely to have performance in line with the average performance measured through cross-validation. The downside is that your final model consists of n models stuck together, making it harder to understand and less efficient. But if you don’t have much data, and you can deal with poor interpretability and higher inference costs, then this is something to consider.
Final thoughts
I hope this post draws attention to the importance of thinking about how you will use data in an ML project, particularly if you don’t have much of it. Rushing in and using a vanilla train/validate/test split only really works in simple situations in which you want to train and evaluate a single model. If you want to train, evaluate and compare multiple models, then you really need extra data split(s) to support this. And while cross-validation can help in some ways, it’s only really designed to evaluate models, not to select them. If you want to select a model to use, then again you’ll need extra data. Either way, it’s important to get the splits right at the start of your project.
See my machine learning pitfalls guide for more on this topic.
Kudos to the Artful Dodger and Craig David.
There are studies who claim that adaptive overfitting is not a problem in imagenet. My initial intuition was that same test set has been used for decades, there was ample opportunity for overfitting, so it must have occurred. But, alas, it doesn't seem to have happened - I find that quite puzzling. Do you have any thoughts?
See for example: Recht, B., Roelofs, R., Schmidt, L. & Shankar, V.. (2019). Do ImageNet Classifiers Generalize to ImageNet? https://proceedings.mlr.press/v97/recht19a.html