


ML Pitfalls #2: LLMs can't spot ML pitfalls


This second entry in my new ML Pitfalls series follows on from a short post I wrote last year entitled Can LLMs spot machine learning pitfalls?, which looked at whether Google’s Gemini could spot a simple data leak in some machine learning code. To summarise: it couldn’t.
Intrigued by this, I talked to some colleagues1 about doing a broader study into how well LLMs spot common ML mistakes in code. This resulted in a study involving 20 pitfalls and 4 LLMs, recently posted on arXiv2.
For those who don’t want to read through this 30 page paper, here’s a brief summary of our findings: LLMs aren’t good at spotting mistakes in ML code. Which is worrying. After all, if LLMs can’t spot mistakes, then this doesn’t give much confidence in their ability to generate code that is error-free3.
Here’s a key table from the paper:
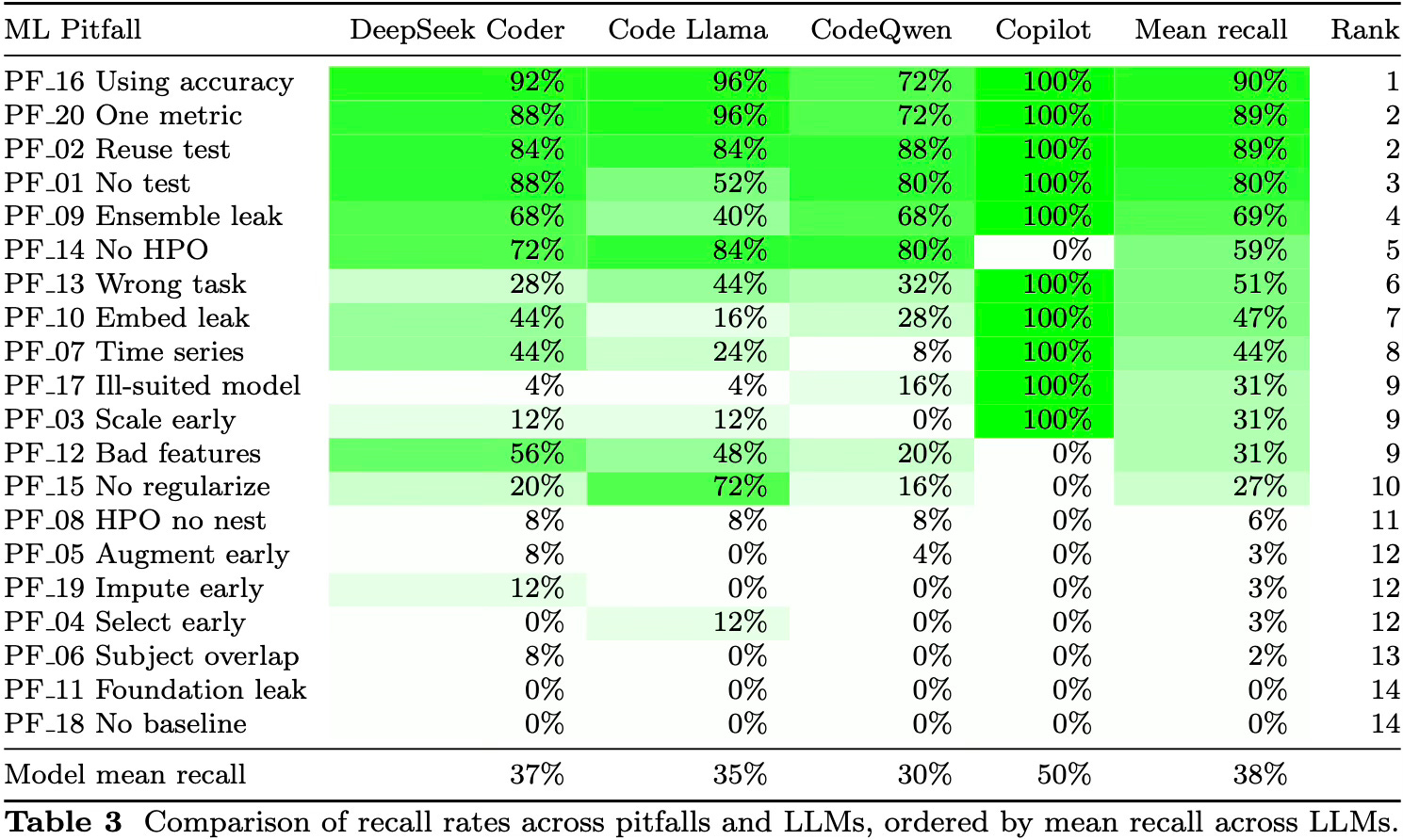
This shows the average recall4, i.e. ability to correctly spot each pitfall, of the four LLMs5 over a number of attempts6. From the mean recall figures shown at the bottom, you can see they didn’t do well. The best performing model (at least by this metric) was Github Copilot7, and it only successfully spotted half of the 20 pitfalls8.
It’s interesting to dig down and see which pitfalls were and weren’t spotted by the LLMs. Generally speaking, they were good at spotting elementary mistakes — things like using accuracy with imbalanced data (PF_16 in the table) or using only a single metric (PF_20), plus issues like not using independent test data (PF_01) or repeatedly using the same test data (PF_02). That is, the kind of concepts that people learn early in their ML education.
They were less good at spotting pitfalls to do with model or component choices. These appear around the middle of the recall-ordered table above. This includes errors of practice like not doing any hyperparameter optimisation (PF_14), using a classification model for a regression task (PF_13) and ignoring temporal dependencies in time series data (PF_07). These are mistakes that tend to occur when people are just starting to apply their knowledge of ML to practical problems.
The lower part of the table contains a lot of pitfalls that could lead to data leaks. Here the LLMs did worst, often with zero recall. This includes doing augmentation (PF_05), data-dependent imputation (PF_19), and feature selection (PF_04) before splitting off the test set, and data contamination from pre-training (PF_11). Data leaks are a major source of failure in real world ML projects, even for more experienced practitioners.
So, in a nutshell, LLMs are pretty good at spotting basic problems, but they’re not good at spotting the ones that actually cause problems in the industrial and academic use of ML, and in this regard the use of LLMs to critique ML code is itself an ML pitfall. They’re probably useful early in ML education, but are not currently good enough to spot the kind of problems that ML practitioners commonly run into.
It may be tempting to predict that LLMs will get better at spotting pitfalls as their architectures develop and their parameter counts further increase. After all, this seems to have been the case with many LLM use cases. However, I’d be wary of saying this is also true of ML pitfalls, since the limitations of LLMs here arguably lie more in their training data than their underlying reasoning abilities. People make a lot of mistakes when writing ML code, and this means that a significant proportion of the ML code on the internet — which these LLMs were trained on — exhibit the pitfalls we’re trying to avoid. Or to put it another way: garbage in, garbage out.
You can see a hint of this in the comparison between the models in the table. Although Github Copilot does do better than the open models, it doesn’t do that much better, despite being orders of magnitude larger9. Presumably this is because it was trained on much the same error-laden data as the open models, and extra parameters are insufficient to compensate for this.
Which is not to say that LLMs are fundamentally incapable of spotting ML pitfalls, but I suspect that if we want them to be good at this, then we’ll need to train them better. In the meantime, we should all be careful when using LLMs to help with our ML coding, and not assume they know what they’re talking about.
Author list: Smitha Kumar, Michael A. Lones, Manuel Maarek, Hind Zantout. Smitha did most of the practical work as part of her PhD.
Disclaimer: the paper is currently under review, so this is not a peer-reviewed version.
Note that this study did not look explicitly at the ability of LLMs to generate correct code. However, we did use a semisynthetic approach to generate code samples for the LLMs to critique, with a different LLM generating our initial code samples. In many cases, it was happy to generate pitfall-laden code without being asked to.
In the previous post in this series, I said that recall in general shouldn’t be used without precision. However, in this case, we were only looking at the LLM’s ability to spot pitfalls that we know are present in code, i.e. true positives and false negatives.
We used three open LLMs and one commercial LLM service. The focus on open LLMs was to do with our particular interests in educational use cases, and the potential for fine-tuning and deploying specialist models within universities.
To compensate for non-determinism, each open LLM was given 5 attempts at 4 different temperature settings, and Copilot was given 5 attempts at one temperature setting (because temperature wasn’t configurable). The values show the means.
Not to be confused with Microsoft Copilot, although Github is owned by Microsoft, and both products use OpenAI’s GPT-4 models, so they have much in common. GitHub Copilot is specifically designed to work with code. Microsoft Copilot also works with code, but not specifically. Confusing, eh?
In case you’re wondering why it’s always 0% or 100% for Copilot, this was due to the lack of a configurable temperature setting. The default setting seems to be very low, meaning that it produces the same output every time.
The internet reckons that GPT-4 (used in Copilot) has more than a trillion parameters. The open models we used have between 7 and 34 billion. Quite a big difference!
I just want you to know that I look forward to catching up on your writing during my weekly commute home. Always a fun read!