
Neural networks: everything changes but you

Neural networks are popular these days. Yet, at the same time, fewer people call them neural networks. It’s much more fashionable to talk about deep learning, transformers and large language models (LLMs). But are these fundamentally new things? Would a neural network researcher from 50-or-so years ago, flash frozen in a freak ice fishing accident, wake up to discover something they wouldn’t recognise?
For the most part1, neural networks trace their origins back to the work of McCulloch and Pitts in the 1940s, though it wasn’t until Rosenblatt’s perceptron models in the late 50s and early 60s that artificial neurons started to resemble those we see today: capable of working with continuous numbers, making use of non-linear activation functions, and having weights on their inputs. Two other important milestones then followed. The first, only a few years later2, was the development of multilayer perceptrons (MLP), which involve stacking layers of neurons on top of each other. The second, mostly in the early 1980s3, was the invention of backpropagation as a way of training an MLP’s weights. All of these things, in one form or another, are still present in modern neural networks.
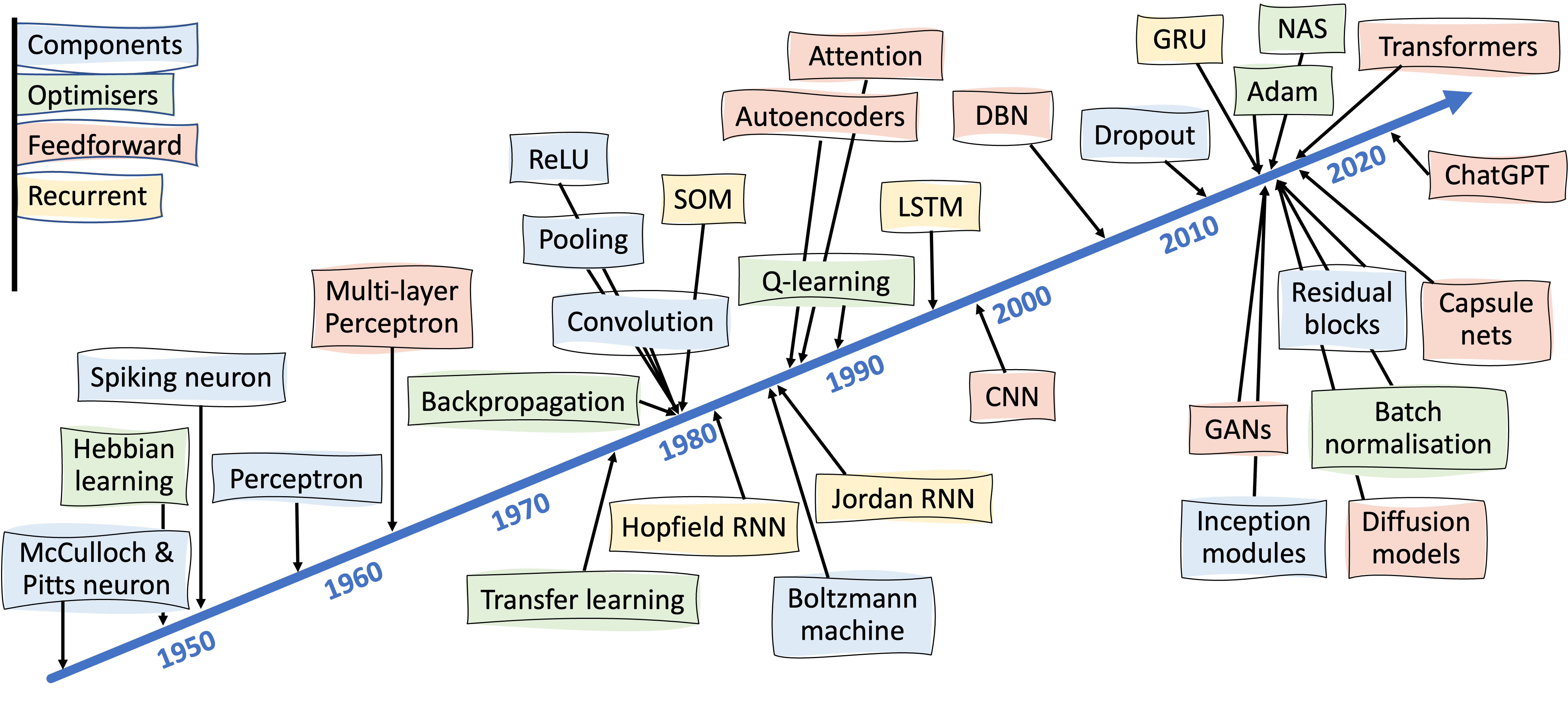
So what’s changed since then? From a contemporary perspective, the main developments have been in the use of convolution and self-attention, which are central components of convolutional neural networks (CNNs) and transformers, respectively. Yet both of these also trace their origins back to the 1980s, so would not be much of a shock to our ice person. Convolution was first used within Fukushima’s Neocognitron, which also introduced pooling and the rectified linear unit (ReLU), both key components of later CNN architectures. Self-attention builds on earlier ideas of attention, which were developed in the late 1980s and early 1990s, and became a central component of recurrent neural architectures such as the long-short term memory (LSTM). Other recent developments also build heavily on existing ideas. For instance, modern neural network training algorithms like stochastic gradient descent (SGD) and Adam are really just tweaks of backpropagation, with some other (fairly old) ideas from optimisation thrown in. The use of latent spaces — another key feature of transformer models — also dates back to the 80s and 90s.
So, I would argue there have been few fundamental developments since then. Instead, the field has mostly focused on scaling-up existing ideas. That is, you won’t find much in a modern transformer that isn’t familiar to our ice person, but the size and complexity of modern transformers could be overwhelming. Back in their day, MLPs had one or two hidden layers. Today, GPT4 has 120 layers. They would have been dealing with perhaps 10s of neurons. GPT4 has trillions. With this has come a huge change in capability. Back in the 80s, neural networks were barely capable of discriminating images of numeric digits. Nowadays we have LLMs, which seem capable of almost anything.
But if there haven’t been any fundamental changes, what enabled this upscaling to occur? In part, this was due to more effective combinations of existing ideas. For instance, Yann LeCunn’s LeNet architecture, commonly seen as the start of the modern CNN era, combined convolution and pooling layers from the Neocognitron with the use of backpropagation — resulting in something that could both analyse image data and be reliably trained. AlexNet added in ReLU units (again first used in the Neocognitron) to produce something that could be reliably trained over a greater number of layers. ResNet then threw in “residual connections” to increase the number of layers even further, building on the idea of skip connections in MLP. However, the other important part of the equation is processing power. That is, the enormous number of parameters in a modern deep learning model are of no use if there’s not enough processing power (or data) to train them. The development of cloud computing, and the offloading of matrix operations to GPUs and TPUs, have both been instrumental in this respect.
Our ice person might also be surprised at the directions neural networks haven’t gone in. The 1980s immediately followed the first AI winter, and became a hot-bed of new ideas. Many of these emanated from recent understanding of how biological brains work, including Grossberg and Carpenter’s adaptive resonance theory, Kohonen’s self-organising maps (SOM), and early ideas of reservoir computing, not to mention ideas from broader understanding of how natural systems work, such as Hopfield networks and Boltzmann machines. Although some of these continue to be of interest to niche communities, none of them really play a part in mainstream deep learning — which, for the most part, has focused on scaling up the biologically-simplistic perceptron model.
And this seems a shame to me. Sure, transformer models have been hugely successful, and LLMs can do amazing things. But, in the long-run, a focus on scaling up old ideas could place a limit on the abilities of AI. Whilst modern neural networks are often compared to brains, they contain little that would be familiar to a neuroscientist, and this is only partly due to our limited understanding of how brains work4. For instance, spiking neural networks are a popular model among researchers who model and simulate brain circuits, and are thought to be a good model of how neurons actually communicate with each other. They’ve also been used to solve hard computational problems, and there have been various attempts to scale them up and make them more efficient. However, real progress is hard to achieve in part because there are so few people working in this area compared to mainstream deep learning.
The hype cycle has a lot to answer for here. Thanks to the regular purging of people who work in neural networks, there has been an inevitable loss of diversity. At the start of each cycle, the study of neural networks almost starts anew, with a myopic focus on whatever works best at the moment.
But at least this lack of change means our ice person won’t feel left behind.
Though early ideas can be traced back to Alan Turing, like most ideas in computer science.
This is a little hard to date, but seems to have happened a lot earlier than most people think. For example, multilayer models are mentioned in Rosenblatt’s 1962 work, Perceptrons and the Theory of Brain Mechanisms.
Invented somewhat contemporaneously by Paul Werbos and the group of Rumelhart, Hinton and Williams, though sadly for Werberos mostly now associated with the latter.
A big hole in our understanding is how the brain actually learns, though most people agree that it doesn’t resemble backpropagation.
I think embedding vectors and encoder-decoders deserve a mention as they were really important in the transformers underlying the meteoric success of LLMs. I'm not sure your ice fisher would recognise them. As one who was such an angler back in the 80s, I was astonished at how successful they were when I first encountered them a decade ago and I still struggle to grasp how they do what they do 😉