
REFORMS, a guide to doing ML-based science (but not just science)

I mentioned REFORMS briefly in a previous post. Now that it’s just been published in the journal Science Advances, I thought I’d say a little more, and try to explain why it’s important for ML practitioners, scientists and the end users of ML and science.
REFORMS is a slightly contrived acronym for “consensus-based recommendations for machine-learning-based science”1. The core issue it’s trying to address is that people keep doing things wrong when applying ML. These mistakes often go unnoticed, and they lead to ML models being deployed which are not fit for purpose, and which sometimes have the capacity to be dangerous — think autonomous vehicles, medical devices, financial trading bots, and the consequences of these things not working properly.
Misapplication of ML is a topic I’ve been raising for some time2, but hopefully the author list demonstrates that it’s not just me who cares about this problem. If you take a look, you’ll see authors from a string of top universities3, plus important centres of applied research such as Microsoft and the Mayo Clinic, showing that there’s broad concern about the dangers surrounding ML practice. In a nutshell, our goal is to address this problem by getting ML practitioners to reflect more on what they are doing. Whilst we don’t stipulate exactly how REFORMS should be used, some of the potential use cases are in education (informing people about how they should do ML), regulation (satisfying regulators that a product of ML is fit for purpose) and publication (satisfying reviewers that an ML pipeline described in a paper is valid).
At the heart of REFORMS is a checklist — that is, something you work through, and respond to each item to show you’ve adequately considered it. More specifically, it’s a checklist of things that should be done when applying ML. Even more specifically, it was written for people applying ML in science, because science is an area in which ML practice is particularly poor. For instance, a recent article in the leading science journal Nature describes science as undergoing a reproducibility crisis due to the widespread failure of scientists to be able to reproduce the results of ML-based scientific studies. Given that science influences our lives in all sorts of ways, this is clearly not a good thing.
So how did this problem come about? Well, I’d say it’s a consequence of two things. First, there’s a lot of incentives to apply ML in science. ML often outperforms traditional methods for data analysis, and it often does this in quite novel ways. To a scientist, this combination screams “Publication!”4. So, this ensures there are plenty of scientists trying to apply ML to problems in their fields. Second, most scientists are not trained in ML methods. Rather than get an expert to help out, they often try it out for themselves — and given the accessibility of many ML frameworks, this is quite possible. However, given the ease with which mistakes can occur when applying ML, it is not necessarily a good idea. And so mistakes happen.
This table (taken from the preprint) shows you what the checklist covers:
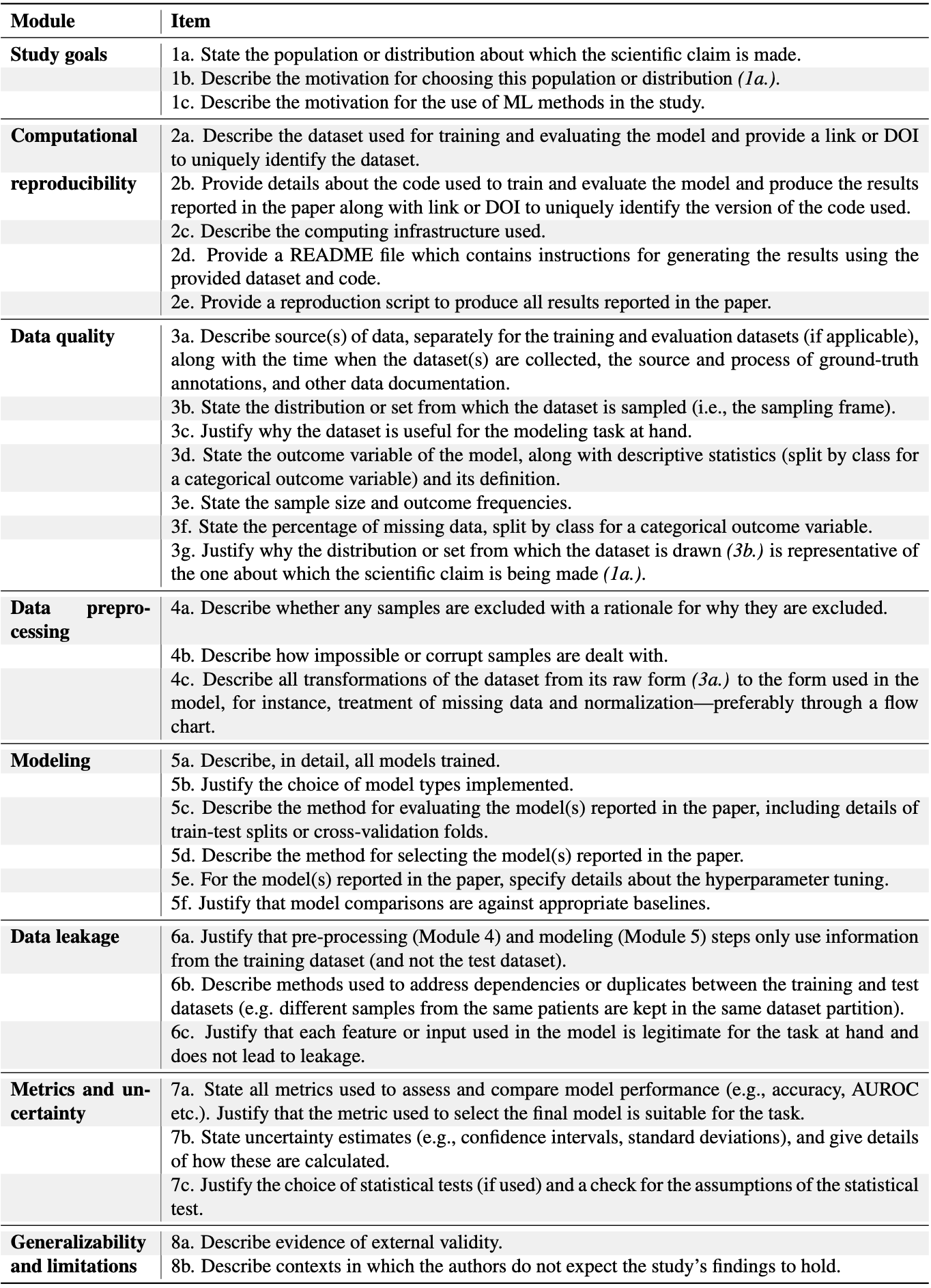
The paper discusses each of these points in detail, and includes lots of citations to places where you can find out more information. So, I’m not going to go through them all here, but I do want to highlight a few points.
First of all, there are several checklist items that encourage practitioners to think about their data and whether this supports the goals of their study. Data is central to any ML-based study. If the data used to train and test models is not representative of the system being studied, then any findings could be misleading or only applicable in certain cases. Think, for example, models developed for clinical medicine that have overfit characteristics of particular groups of patients5. In practice, there are usually significant constraints on the kind of data can be collected, but a common error in ML-based science studies is to ignore this fact and assume that the conclusions generalise beyond the data. They usually don’t!
Quite a few of the items are concerned with avoiding data leaks. This is something I’ve talked about a lot elsewhere, so I won’t repeat myself again. However, data leaks — where information typically leaks in some way from the test set into the train set — are one of the commonest and most damaging errors in applied ML. In a scientific context, they can easily invalidate the conclusions of a study, so it’s always worth being on the lookout for them. Section 6, entitled Data Leakage, really focuses on this, but it’s also touched upon in items 4c, 5c, 5d, 5e and 8a.
Another pet topic of mine is how to compare ML modelling approaches fairly. Comparing models is something that happens a lot in ML-based science, and in general it’s not done fairly, often giving a misleading impression that a newly-introduced approach is superior to existing ones when the evidence simply doesn’t support this. And this is not just an issue for the validity of individual studies, because scientific studies almost always build on other studies, meaning that invalid conclusions can percolate through and affect whole areas of study. Section 7 and item 5f cover this, and emphasise the importance of appropriate metrics, appropriate reporting and appropriate baselines, not to mention the dreaded statistical test.
Last, but definitely not least, is Section 8 on generalisability6 and limitations. The failure of scientific studies to generalise is one of the biggest problems in ML-based science. This includes both the ML models developed, which are often found not to work in practice, and the findings that come from the study, which are often found not to be reproducible. Many common errors contribute to this — including inappropriate data and data leaks — so it’s always worth going well out of the way to make sure this isn’t the case.
And finally, this isn’t just about scientific studies. ML is applied in all sorts of domains, and all of these domains face the same underlying problems. Whilst some sections of REFORMS are less relevant to applied ML in general, I’d argue that most of them are very relevant. So take a look even if you don’t consider yourself to be doing science. The full open access paper is available at this link.
Thanks especially to Sayash Kapoor and Arvind Narayanan for leading on this. Check out their Substack AI Snake Oil for more on the issues surrounding hype in AI and ML.
It used to stand for “Reporting Standards for ML-based Science”, which was a better fit, but the title changed during the review process.
Including in a previous Substack post When Machine Learning Doesn’t Learn, in How to Avoid Machine Learning Pitfalls: A Guide for Academic Researchers, and in Why Doesn’t My Model Work? in The Gradient.
To save you the work: Princeton, Cornell, Duke, NTNU, Northwestern, Stanford, Berkeley, Cambridge, UCSD, Ghent, and of course my own institution, Heriot-Watt.
Scientists generally love to publish things. Even if they don’t, it’s one of the currencies of career advancement, so they kind of have to.
The failure of pulse oximeters to work on people with different skin pigmentation is a cautionary tale of where this can go.
Or “generalizability” when most of your co-authors are from the US!