
The boring truth about AlphaEvolve

It’s the job of those in the tech industry to big up everything they do. As an academic, I see it as my job to put things back in perspective. Last time I gave this “boring truth” treatment to DeepSeek. This time I’m looking at AlphaEvolve, which Google DeepMind described in their paper as “A coding agent for scientific and algorithmic discovery”. Sounds exciting — but is it?
Well, it kinda is, and kinda isn’t. Their paper talks about how they used it to discover novel solutions to a whole bunch of problems. Obscure problems that most people have never heard of, but important problems nonetheless. These include a cheaper method to multiply 4x4 complex matrices, a better algorithm for solving shape packing problems, and a method for optimising the Google data centre.
However, if I were to be critical, I’d say there’s a lot of focus on the problems they solved, and not so much on the underlying novelty of their contribution. Solving problems better than humans is not a contribution in itself — those of us who hang around evolutionary algorithms have been doing this pretty much forever. Check out the annual Humies awards if you want the gory details; 2018 was a vintage year1.
Given it’s called AlphaEvolve, there’s unsurprisingly a lot of evolutionary algorithm about it. Specifically, it has a lot of genetic programming (GP) about it, which is a group of evolutionary algorithms people use to evolve code2. If I were being injudicious, I’d say it’s merely a GP system that uses an LLM to generate and modify programs, something that people had been conspicuously doing for some time before AlphaEvolve came along.
But let’s get away from this academic banter, and take a look at how it works. Here’s a diagram I made. It’s a lot simpler than Google’s, but hopefully gets across the gist3:
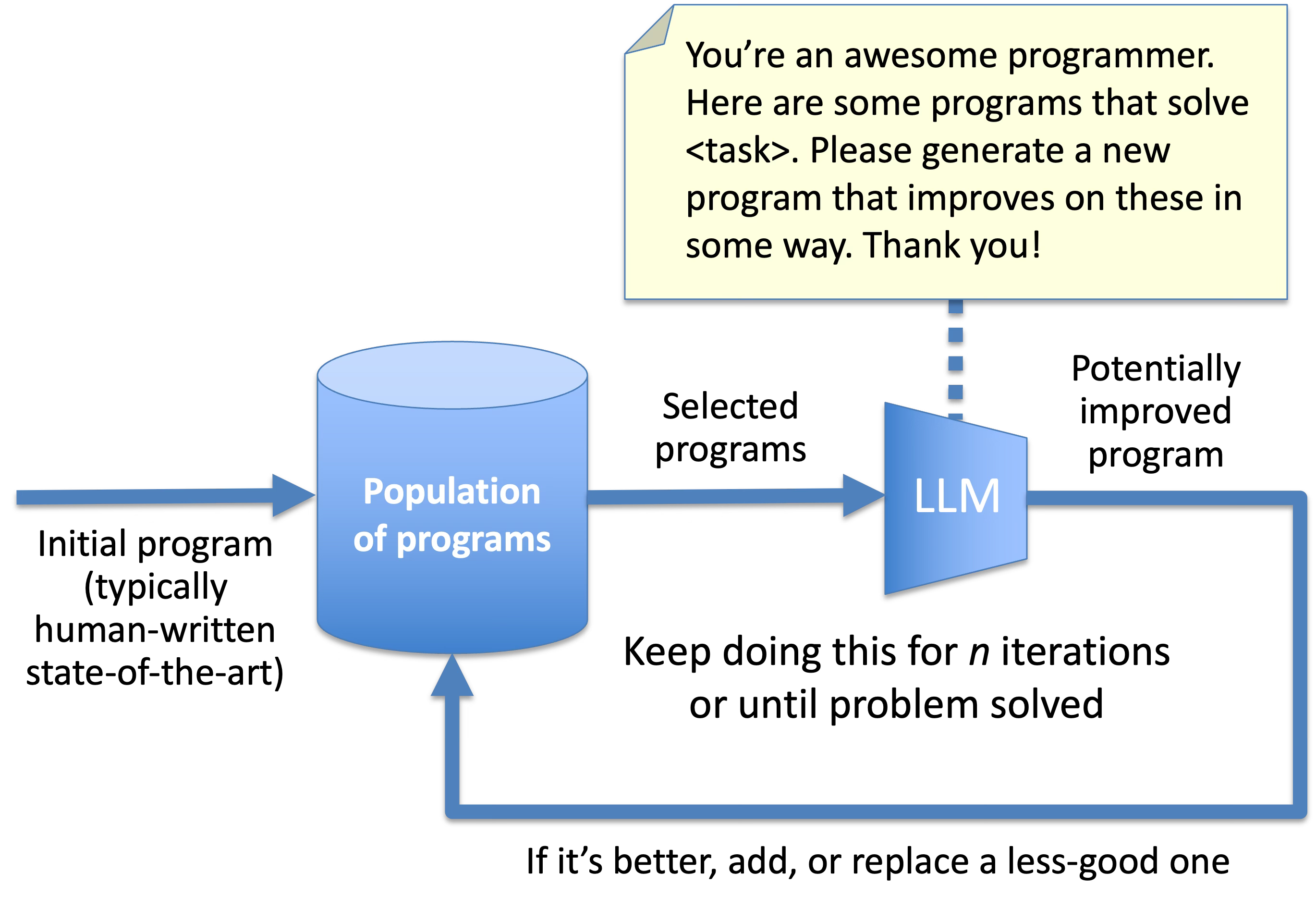
It starts with a human-written program that solves some task: not brilliantly, but a starting point. This seeds the population. It then gets passed to an LLM, which is asked to improve it. The LLM-generated program gets added to the population. Then the LLM is given both programs, and again asked to suggest an improvement. This is added to the population. Do this sort of thing for a while, but only pass the LLM the better programs in the population, so that it’s focusing on improving its best efforts so far, and remove the less good ones so that you’re not keeping too much dross. But occasionally throw in some of the less good ones to increase the diversity of programs the LLM’s working with. Keep doing this until you get bored.
At the heart of this is an evolutionary process. That is, a population of solutions to some problem which are being progressively mutated and selected according to Darwin’s good old survival of the fittest principle. A big difference though is that mutation is not randomly changing bits of a solution in the way of a standard evolutionary algorithm. Rather, an LLM is being used to mutate them in a more intelligent way4.
Though I use the term “mutation” lightly, since in principle the LLM can do whatever it likes with the input it receives. It might change one of the programs it’s given, it might recombine elements of the programs, or it may ignore them completely and just spew out its own preferred solution to the task it’s given. Either way, it tends to produce something that is complete, syntactically valid, and readable. Which is not something you can say about classic GP systems, which produce the weirdest things, many of which don’t work and go straight into the evolutionary rubbish bin.
But the big ticket item that the LLM is bringing to the party is contextual knowledge. It knows, sort of, everything that humans know about the problem it’s being asked to solve. Which means it can inject this knowledge and not worry too much about the usual try-random-stuff-and-see-if-it-works approach of evolutionary algorithms. However, this is also a weakness of LLMs, since they only know how to solve tasks in ways which humans have already solved them. Right?
Well, not entirely. Conventional wisdom says that LLMs are not great for discovering new things, but Google’s results show that they can, within certain bounds, go beyond existing human solutions and solve things in better ways. And, to some degree, in novel ways. And this is really due to combining the LLM with an evolutionary algorithm. The evolutionary part continually pushes the LLM towards the best things it’s come up with so far (plus some other bits and pieces5) and urges it to go further. And sometimes this pushes it beyond existing human knowledge.
How far beyond existing human knowledge it can go is an open question, and actually one of the good things about Google’s hype is that lots more people are investigating this. I’ll be interested to hear what they find. However, I imagine there are limits, and I suspect we’ll also need to maintain more traditional evolutionary algorithm components (like random mutation) if we’re really going to push the boundaries.
Incidentally, if you want to try it out for yourself, there’s an open source version called OpenEvolve, which you can use with a locally-hosted LLM — thanks to Asankhaya Sharma for kicking off the project.
Yes, I won it :-)
Even more so, it has a lot of Genetic Improvement (GI) about it, which is an approach that uses GP to patch existing programs so that they work better.
AlphaEvolve has a bunch of bells-and-whistles that aren’t shown here. This includes the use of multiple LLMs, asking LLMs to improve prompt wording, and getting LLMs to evaluate solutions (thereby augmenting the usual fitness function).
Intelligent design meets evolution? Dawkins would be horrified.
AlphaEvolve also uses a bunch of other well-known techniques from the evolutionary algorithm universe to preserve behavioural diversity within the population.
Do you know of any relatively simple concrete examples in which AlphaEvolve transforms a seed program into something significantly better? Thanks.